Hadoop framework gồm 4 module:
- Hadoop Common: Đây là các thư viện và tiện ích cần thiết của Java để các module khác sử dụng. Những thư viện này cung cấp hệ thống file và lớp OS trừu tượng, đồng thời chứa các mã lệnh Java để khởi động Hadoop.
- Hadoop YARN: Đây là framework để quản lý tiến trình và tài nguyên của các cluster.
- Hadoop Distributed File System (HDFS): Đây là hệ thống file phân tán cung cấp truy cập thông lượng cao cho ứng dụng khai thác dữ liệu.
- Hadoop MapReduce: Đây là hệ thống dựa trên YARN dùng để xử lý song song các tập dữ liệu lớn.
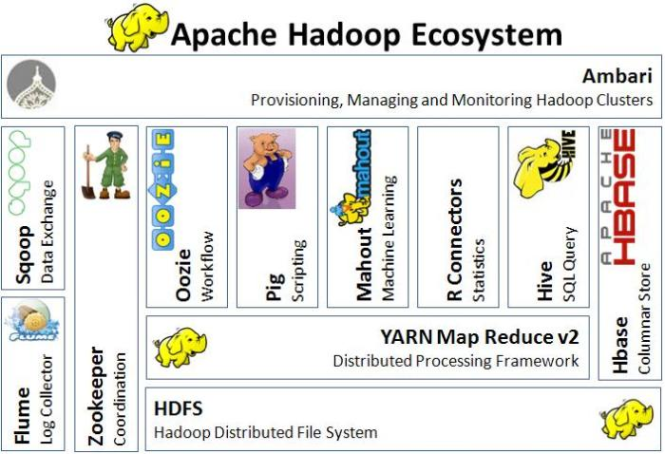
Có thể sử dụng sơ đồ sau để mô tả bốn thành phần có trong Hadoop framework:

2.1 MapReduce
Hadoop MapReduce là một framework dùng để viết các ứng dụng xử lý song song một lượng lớn dữ liệu có khả năng chịu lỗi cao, xuyên suốt hàng ngàn cụm máy tính.
Thuật ngữ MapReduce liên quan đến hai tác vụ mà chương trình Hadoop thực hiện:
- Map: đây là tác vụ đầu tiên, trong đó dữ liệu đầu vào được chuyển đổi thành tập dữ liệu theo cặp key/value.
- Reduce: tác vụ này nhận kết quả đầu ra từ tác vụ Map, kết hợp dữ liệu lại với nhau thành tập dữ liệu nhỏ hơn.
Thông thường, kết quả input và output được lưu trong hệ thống file. Framework này sẽ tự động quản lý, theo dõi và tái thực thi các tác vụ bị lỗi.
MapReduce framework gồm một single master JobTracker và các slave TaskTracker trên mỗi cluster-node. Master có nhiệm vụ quản lý tài nguyên, theo dõi quá trình sử dụng tài nguyên và lập lịch quản lý các tác vụ trên slave , theo dõi chúng và thực thi lại các tác vụ bị lỗi. Những máy slave TaskTracker thực thi các tác vụ được master chỉ định và cung cấp thông tin trạng thái tác vụ (task-status) để master theo dõi.
JobTracker là một điểm yếu của Hadoop Mapreduce. Nếu JobTracker bị lỗi thì mọi công việc liên quan sẽ bị ngắt quãng.
2.2 HDFS (Hadoop Distributed File System)
+ Hadoop có thể làm việc trực tiếp với bất kì hệ thống dữ liệu phân tán như Local FS, HFTP FS, S3 FS, và các hệ thống khác. Nhưng hệ thống file thường được dùng bởi Hadoop là Hadoop Distributed File System (HDFS).
+ Hadoop Distributed File System (HDFS) dựa trên Google File System (GFS), cung cấp một hệ thống dữ liệu phân tán, được thiết kế để chạy trên các cụm máy tính lớn (gồm hàng ngàn máy tính) có khả năng chịu lỗi cao.
+ HDFS sử dụng kiến trúc master/slave, trong đó master gồm một NameNode để quản lý hệ thống file metadata và một hay nhiều slave DataNodes để lưu trữ dữ liệu thực tại.
Một tập tin với định dạng HDFS được chia thành nhiều block và những block này được lưu trữ trong một tập các DataNodes. NameNode định nghĩa ánh xạ từ các block đến các DataNode. Các DataNode điều hành các tác vụ đọc và ghi dữ liệu lên hệ thống file. Chúng cũng quản lý việc tạo, huỷ, và nhân rộng các block thông qua các chỉ thị từ NameNode.
HDFS cũng hỗ trợ các câu lệnh shell để tương tác với tập tin như các hệ thống file khác.
3. Hadoop hoạt động như thế nào?
Giai đoạn 1
Một user hay một ứng dụng có thể submit một job lên Hadoop (hadoop job client) với yêu cầu xử lý cùng các thông tin cơ bản:
- Nơi lưu (location) dữ liệu input, output trên hệ thống dữ liệu phân tán.
- Các java class ở định dạng jar chứa các dòng lệnh thực thi các hàm map và reduce.
- Các thiết lập cụ thể liên quan đến job thông qua các thông số truyền vào.
Giai đoạn 2
Hadoop job client submit job (file jar, file thực thi) và các thiết lập cho JobTracker. Sau đó, master sẽ phân phối tác vụ đến các máy slave để theo dõi và quản lý tiến trình các máy này, đồng thời cung cấp thông tin về tình trạng và chẩn đoán liên quan đến job-client.
Giai đoạn 3
TaskTrackers trên các node khác nhau thực thi tác vụ MapReduce và trả về kết quả output được lưu trong hệ thống file.
4. Ưu điểm của Hadoop
- Hadoop framework cho phép người dùng nhanh chóng viết và kiểm tra các hệ thống phân tán. Đây là cách hiệu quả cho phép phân phối dữ liệu và công việc xuyên suốt các máy trạm nhờ vào cơ chế xử lý song song của các lõi CPU.
- Hadoop không dựa vào cơ chế chịu lỗi của phần cứng fault-tolerance and high availability (FTHA), thay vì vậy bản thân Hadoop có các thư viện được thiết kế để phát hiện và xử lý các lỗi ở lớp ứng dụng.
- Các server có thể được thêm vào hoặc gỡ bỏ từ cluster một cách linh hoạt và vẫn hoạt động mà không bị ngắt quãng.
- Một lợi thế lớn của Hadoop ngoài mã nguồn mở đó là khả năng tương thích trên tất cả các nền tảng do được phát triển trên Java.
Một số site tham khảo về hadoop:
https://ongxuanhong.wordpress.com/2015/11/15/top-free-hadoop-tutorials/
https://ongxuanhong.wordpress.com/2015/08/17/nen-chon-hadoop-hay-spark-cho-he-thong-big-data/
http://saphanatutorial.com/hadoop-1-0-vs-hadoop-2-0/
http://phamquan.com/big-data/big-data-co-ban
http://www.corejavaguru.com/bigdata/index
How to Install and Configure Apache Hadoop on a Single Node in CentOS 7
https://www.edureka.co/blog/install-hadoop-single-node-hadoop-cluster
Leave a Reply